La variabilidad de los tratamientos dentales en una población militar española y su importancia para la estimación de la probabilidad de identificación dental
The diversity of dental clinical features in an Spanish military population and its implications for dental identification

Cuad Med Forense. 2008; 14(53-54):223-233
Fecha de recepción: 25.ENE.09; Fecha de aceptación tras revisión interna: 28.ENE.09
RESUMEN
La identificación dental se consigue cuando del proceso de comparación de los datos dentales antemortem y postmortem se concluye que existen coincidencias suficientes, y ninguna discrepancia absoluta, que permitan al odontólogo forense alcanzar un grado de certeza suficiente para establecer la identidad entre el cadáver y los datos clínicos dentales del paciente. Sin embargo, una de las principales dificultades con las que se encuentra la identificación dental es la escasez de datos epidemiológicos sobre la distribución de frecuencias de las diversas situaciones clínicas (patologías y tratamientos), para cada pieza dentaria en poblaciones de distinto origen, por lo que no es posible, hasta el momento presente, estimar el grado de probabilidad en una identificación dental. Con la finalidad de contribuir al conocimiento de la diversidad de las distintas situaciones clínicas dentales de la población española, se ha desarrollado una base de datos con las características clínicas de cada pieza dentaria en una población militar que comprende un total de 2091 individuos. Se presentan los resultados encontrados, empleando un sistema de codificación detallado y otro genérico, de los posibles tratamientos dentales y se obtienen conclusiones sobre las frecuencias y distribución de las patologías y tratamientos dentales. Se concluye la importancia de la existencia de estas bases de datos para la estimación de la probabilidad de identificación dental.
Palabras clave: Odontología Forense, Diversidad dental, Identificación Humana.
ABSTRACT
Dental identification is established when dental antemortem data are compared to postmortem dental charts and a high number of coincidences are found. Moreover, if any discrepancies are detected, they have to be explained. Therefore, they are some limitations to achieving a consistent dental identification probability due to the fact that there are not enough epidemiological data bases about dental treatments or dental pathologies for each tooth obtained from different origin populations where we could estimate accurately the likehood ratio for a dental identification. In order to contribute to a better understanding of dental characteristics in Spain, a dental data base from an Spanish military population has been constructed. A codification system has been developed and 2091 cases have been introduced into the system. Results presented in this paper shown the frequencies and distributions of dental treatments and pathologies in the population explored. It is concluded that it is of great importance the development of those dental data bases for application on estimation of probabilities for dental identification.
Key words: Forensic Odontology, Dental diversity, Human identification.
Nota: Los datos incluidos en este trabajo no representan la opinión de ninguna institución pública, civil o militar, y su uso apropiado es responsabilidad exclusiva de los autores.
Introducción
La identificación dental se consigue cuando del proceso de comparación de los datos dentales antemortem y postmortem se concluye que existen coincidencias suficientes, y ninguna discrepancia absoluta, que permitan al odontólogo forense alcanzar un grado de certeza suficiente para establecer la identidad entre el cadáver y los datos clínicos dentales del paciente [1-5]. Al realizar la comparación diente a diente se registran las similitudes y las discrepancias. Las similitudes son características clínicas dentales antemortem y postmortem que coinciden. Las discrepancias son hallazgos que no concuerdan aunque algunas de ellas pueden tener alguna explicación. Si las discrepancias pueden explicarse, la identificación puede ser posible. Cuando las discrepancias son totalmente inexplicables, y no ha existido ningún error en el proceso, la identificación no es posible con esa persona y queda excluida. Por tanto, la identificación dental se hará en base a que no existan discrepancias absolutas, a que las discrepancias relativas se pueden explicar con una lógica razonable, y que existan puntos de coincidencia (similitudes). Aunque de la lectura de la literatura científica sobre el tema no se deduce el requerimiento de un número mínimo de coincidencias [1,6-7], la conclusión de identidad será tanto más consistente cuanto mayor sea el número de puntos de coincidencia o más inusual sea el hallazgo. Existen puntos de coincidencia ordinarios (características que se presentan de manera frecuente en la población general, por ejemplo una obturación oclusal en el primer molar permanente), y extraordinarios, definidos por Keiser-Nielsen [4] como aquellas características que están presentes en menos del 10% de la población general.
En otras especialidades de las ciencias forenses, como ocurre en la genética forense, es posible el cálculo de la probabilidad de identificación o la razón de verosimilitud (likehood ratio) porque se dispone de las frecuencias de los diversos marcadores génicos en poblaciones concretas [8-10]. Sin embargo una de las principales dificultades con las que se encuentra la identificación dental es la escasez de datos epidemiológicos sobre la distribución de frecuencias de las diversas situaciones clínicas (patologías y tratamientos), para cada pieza dentaria en poblaciones de distinto origen. En los últimos años se han publicado varios trabajos sobre las frecuencias de los patrones de tratamientos y patologías dentales en población militar americana [11-13], coreana [14] y española [15]. Con estos estudios se pretende contribuir a la estimación de las probabilidades de la diversidad de patrones de tratamientos de las poblaciones sometidas a estudio.
Al menos teóricamente, las posibles combinaciones de las condiciones clínicas (piezas sanas, obturaciones, ausencias, etc.) en la dentición humana pueden alcanzar valores muy elevados que podrían ascender a trillones de posibles patrones dentales [4, 6, 11-12], cifras similares a las que se describen para los polimorfismos del ADN mitocondrial [8,12] y que, de conocerse su distribución, permitirían obtener con precisión el grado de certeza en una identificación dental [16,17].
Pero no se puede olvidar que las condiciones clínicas dentales no ocurren de forma independiente ni con la misma probabilidad en cada una de las piezas dentales [12] por lo que con fines de identificación dental sería recomendable la valoración del conjunto de las condiciones dentales de una dentición. El procedimiento de identificación es similar tanto en casos de víctimas desaparecidas en circunstancias de grandes catástrofes como en aquellas situaciones forenses de víctimas aisladas en las que la comparación dental se tiene que realizar con los datos clínicos de una población más amplia de posibles candidatos [5, 6,18-21].
El objetivo de esta investigación es el desarrollo y construcción de una base de datos dentales de una población militar que nos permita conocer las frecuencias y distribuciones de las distintas situaciones clínicas o patologías que se presentan en cada pieza dentaria y, a partir de ellas, poder calcular las probabilidades de cada uno de los distintos patrones dentales y su variabilidad en el grupo poblacional de referencia. Estos datos servirán de base para el cálculo de las frecuencias poblacionales de los distintos patrones dentales y, en consecuencia, se podrán realizar estimaciones matemáticas de las probabilidades y su aplicación al cálculo del grado de certeza en la identificación dental.
Material y métodos
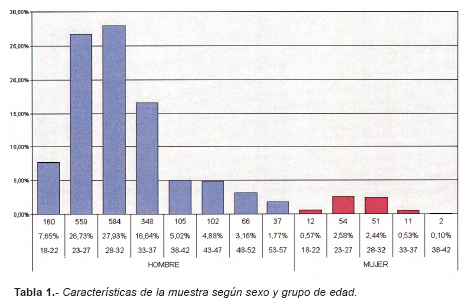
Para la realización de este estudio, se ha partido de las fichas dentales actualizadas de 2091 sujetos pertenecientes a personal militar profesional de las Fuerzas Armadas. Las fichas dentales han sido realizadas durante los últimos 5 años, por un solo oficial odontólogo. La muestra analizada de 2091 militares, corresponde al 1.583% de la población total de las Fuerzas Armadas españolas. La muestra está compuesta por 1961 hombres (93.78%) y 130 mujeres (6.22%), comprendidos en un rango de edad entre 18 (la edad mínima para el ingreso en las Fuerzas Armadas, según la legislación española) y 57 años. La distribución demográfica por edades y sexos se incluye en la Tabla 1.
El estudio se ha elaborado cumpliendo la legislación española vigente sobre Derechos de los pacientes y la protección de datos de carácter personal, y en consonancia con las recomendaciones internacionales sobre investigación clínica incluidas en la Declaración de Helsinki.
La base de datos creada incluye sólo los datos dentales, la edad y sexo de la persona. Los datos dentales utilizados en el presente estudio proceden de la ficha dental que se realiza a todo militar que tenga previsto participar en operaciones fuera de territorio nacional como parte de un reconocimiento médico general. Para efectuar los reconocimientos dentales de la población militar se ha contado con: Fichas dentales de las Fuerzas Armadas, sillón dental o en su defecto camilla de exploración, luz integrada del sillón dental o en su defecto lámparas de exploración complementadas con linterna de exploración médica, espejos dentales desechables de un solo uso, y sondas dentales. Los reconocimientos odontológicos se han realizado en los Servicios Sanitarios de los acuartelamientos militares de las provincias de Almería, Granada, Málaga, Córdoba, Sevilla, Murcia, Alicante y Ciudad Real.
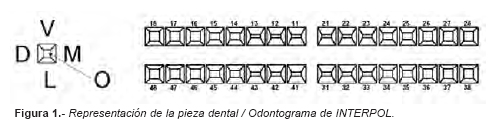
Para procesar dichas fichas, se ha diseñado una Base de Datos informatizada a partir del programa Microsoft Access de Microsoft Office, de entorno Windows. La Base de Datos está concebida para almacenar los odontogramas y actualizarlos. Para codificar los datos dentales se realizó un diseño gráfico tomando como base el dibujo utilizado por INTERPOL en sus formularios de Identificación de Victimas de Catástrofes, debido a su sencillez, universalidad y elevada aceptación. El dibujo, consiste en un cuadrado subdividido en cinco áreas que representan las diferentes superficies de los dientes (Mesial, Distal, Vestibular, Lingual y Oclusal). Este diseño, que carece de elementos anatómicos y/o artísticos, facilita la delimitación de los diferentes tratamientos, eliminando por tanto, condicionantes subjetivos de tamaño y conformación de las caries o restauraciones (Fig. 1).
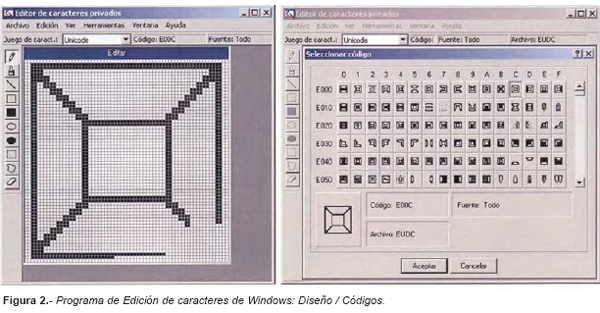
Con la finalidad de que el dibujo sea interpretado por el software de Microsoft Access y poder posteriormente codificar datos que puedan ser valorados estadísticamente, se utiliza el programa de edición de caracteres suministrado por Windows (Fig. 2). Se han diseñado un total de 86 caracteres diferentes que abarca la mayoría de las condiciones clínicas que podemos hallar en todas las piezas dentarias. Se han diseñado, además, dos codificaciones paralelas para cada posible situación clínica que ocurra en cada pieza dentaria. La primera codificación, definida como Detallada, recoge condiciones clínicas específicas, indica materiales empleados y superficies afectadas. La segunda codificación, definida como Genérica, presenta sólo 4 caracteres para simular los casos en los que la información aportada por los odontoestomatólogos es escasa.
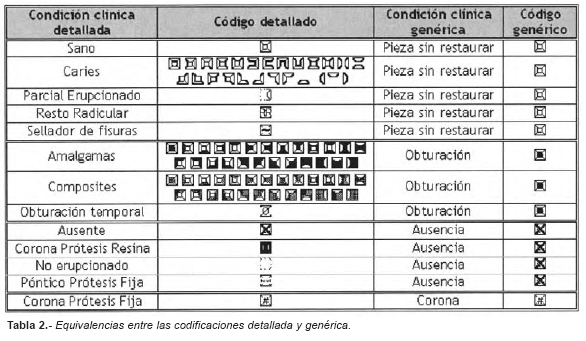
La relación entre las condiciones clínicas que se pueden presentar en cada pieza dentaria, y sus correspondientes equivalencias en las codificaciones Genérica y Detallada definidas se expone en la Tabla 2.
El análisis estadístico de las variables estudiadas incluye la descripción de las frecuencias y estadísticos de tendencia central y dispersión más usuales, para lo que se ha empleado el paquete estadístico SPSS 8.0 para Windows. Los detalles en cuanto a los distintos tratamientos estadísticos empleados se encuentran compilados en Martín y Luna [22].
Resultados
1.1. Codificación dental detallada.
Al analizar cada pieza dentaria en la codificación detallada, se nos presenta una gran cantidad de condiciones clínicas diferentes y una enorme diversidad en las mismas. Hay códigos presentes en todas las piezas dentarias como por ejemplo el sano o el ausente, pero hay otros códigos poco frecuentes, que no aparecen en todas las piezas, como es el caso del sellador de fisuras que, como resulta evidente, no está presente en ningún diente anteroinferior. El número de códigos diferentes encontrados para cada pieza en el presente estudio se representa en la Figura 3.
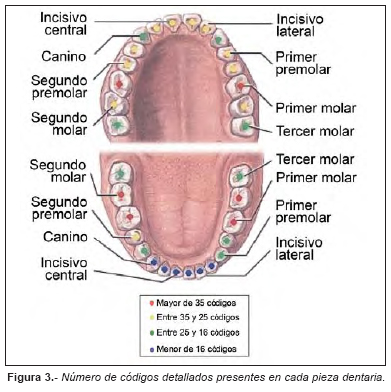
El código más frecuente en las 32 piezas es el sano. Los porcentajes oscilan desde el 98.90% en la pieza 33, hasta el 33.96% en la pieza 38. El segundo código en orden de frecuencia varía según la pieza estudiada; el código ausente es el más frecuente en 17 piezas dentarias, con porcentajes que oscilan desde el 20.09% de la pieza 36 hasta el 0.33% de las piezas 41 y 42. La obturación de composite oclusal predomina en 5 piezas dentarias con porcentajes que oscilan entre el 15.26% de la pieza 47 al 4.21% de la pieza 35. La corona prótesis fija predomina en 4 piezas dentarias, con porcentajes que oscilan entre el 2.87% de la pieza 21 al 1.67% de las piezas 12 y 23. La codificación no erupcionado predomina en 3 piezas dentarias, con porcentajes que oscilan entre el 23.86% de la pieza 28 al 19.08% de la pieza 48. La obturación de amalgama oclusal predomina en 2 piezas dentarias, con unos porcentajes del 12.15% para la pieza 26 y del 10.90% para la pieza 27. La obturación de composite oclusomesial predomina en la pieza 22 con un 2.01%.
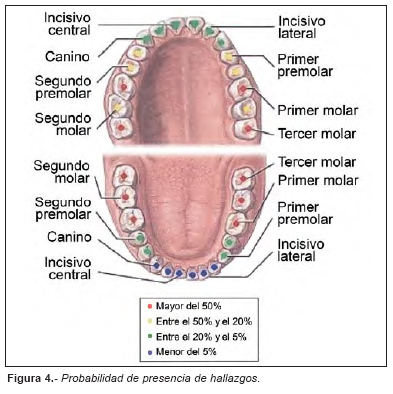
Cualquier situación clínica que presente una pieza dentaria diferente a sano, aporta alguna información de utilidad, por lo que la definimos como hallazgo. La probabilidad de presencia de hallazgos en cada pieza dentaria se representa en la Figura 4.
1.2. Codificación genérica.
Si analizamos las condiciones clínicas observadas en las piezas dentarias utilizando la codificación genérica, se resumen dichas condiciones a sólo 4 códigos. Para ello, convertimos cada código detallado en su correspondiente genérico según las equivalencias expuestas en la Tabla 2.
Las 32 piezas dentarias de los 2091 sujetos de la muestra suponen un total de 66912 dientes analizados. En la presentación total de cada uno de los códigos genéricos obtenemos unas frecuencias del 78.64% (52619 dientes) en la pieza sin restaurar, un 10.55% (7059 dientes) en el código de obturación, un 9.82% (6570 dientes) en el código de ausencia, y un 0.99% (664 dientes) en el código de corona.
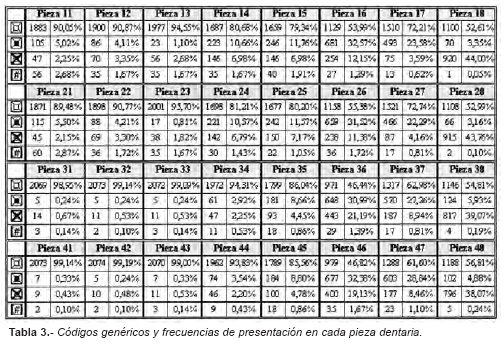
En el estudio individual de cada diente, el código mas frecuente en las 32 piezas dentales, es el de pieza sin restaurar, con porcentajes que oscilan entre el 99.19% en la pieza 42 y el 46.44% en la pieza 36. El segundo código más frecuente es el de obturación (en 20 piezas dentarias) o el código de ausencia (en 12 piezas dentarias). El código de corona es el menos frecuente en todas las piezas exceptuando las piezas 11, 21, 13 y 23 (Tabla 3).
1.3. Estudio de dientes contralaterales.
En odontología, el término de diente contralateral, corresponde a la pieza homónima que está colocada en posición simétrica en la misma arcada dental. Anatómicamente suelen ser idénticos pero simétricos. Los dientes contralaterales tienen la misma conformación, tamaño y posición en la arcada dental, llegando incluso a compartir anomalías de forma, tamaño y posición.
El análisis de los dientes contralaterales se realiza para el total de la muestra. A partir del estudio de la codificación detallada, se obtenía la diversidad de los códigos en las diferentes piezas dentarias (Figura 3).
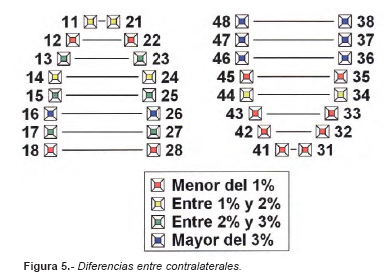
En la codificación genérica, analizamos la diferencia de frecuencias de cada uno de los códigos. Para el código de pieza sin restaurar, las diferencias entre contralaterales tienen un valor máximo del 2.00% para la pareja 18-28 y un mínimo del 0.05% para la pareja 32-42. En el código de obturación, las diferencias oscilan entre un máximo de 1.58% para la pareja 37-47 y un mínimo del 0.0% para la pareja 32-42. Para el código de ausencia, las diferencias entre contralaterales tienen un valor máximo del 2.06% para la pareja 36-46 y un mínimo del 0.0% para la pareja 33-43. Por último, en el código genérico de corona, las diferencias oscilan entre un máximo de 0.86% para la pareja 15-25 y un mínimo del 0.0% para las parejas 13-23, 32-42, 33-43 y 35-45. Además, si acumulamos las diferencias de frecuencias de los cuatro códigos genéricos en cada pareja, obtenemos una diferencia total que nos orienta sobre la similitud que presenta. Estas similitudes oscilan entre el 0.1% de la pareja 32-42 y el 4.11% de la pareja 36-46 (Fig. 5).
Discusión
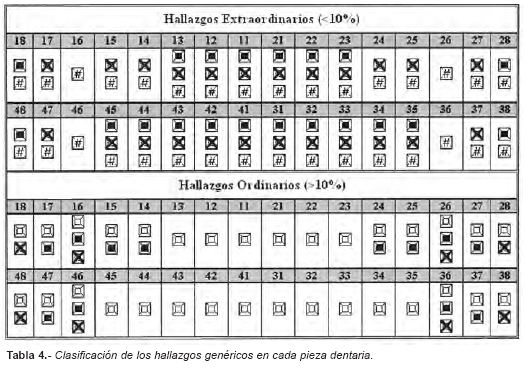
Keiser-Nielsen [4] define como característica «extraordinaria» a aquella condición clínica que ocurre en menos del 10% de la muestra, y con seis de ellas podríamos establecer una identificación positiva. Si seguimos el criterio del citado autor, podríamos afirmar que cualquier hallazgo detallado encontrado en incisivos, caninos o en premolares, tendría la consideración de «extraordinario», y se deduce indirectamente que con sólo 6 de estas piezas dentarias se podría llegar a establecer, al menos teóricamente, una identificación positiva.
Por el contrario, los hallazgos con frecuencias de aparición mayores del 10%, son considerados como «ordinarios», y sería necesaria la presencia de 12 de ellos para establecer identificaciones positivas. Únicamente los molares superiores e inferiores, presentan códigos detallados con frecuencias superiores al 10%. Estos hallazgos «ordinarios» son obturación de composite oclusal en las piezas 16, 17, 26, 27, 36, 37, 46 y 47, obturación de amalgama oclusal en las piezas 16, 17, 26 y 27, ausente en las piezas 16, 18, 26, 28, 36, 38, 46 y 48, no erupcionado en las piezas 18, 28, 38 y 48, parcialmente erupcionado en las piezas 38 y 48, y caries oclusal en la pieza 37 (con un 10.52% alcanza proporciones significativas, pero en la pieza contralateral 47 las proporciones son muy similares 9.18% aunque estadísticamente no sobrepase el límite del 10%, lo que explica la presencia aislada de la pieza 37). Cualquier otro hallazgo diferente en estas piezas dentarias es menor del 10% y tendría la consideración de «extraordinario».
En cuanto a la diversidad de los hallazgos detallados, cuanto mayor sea el número de condiciones clínicas diferentes que pueda presentar una pieza dentaria, mayor será el valor de esa pieza como fuente de información. Un diente con una diversidad elevada tiene más posibilidades de comportarse como elemento diferenciador ante la posibilidad de establecer una identificación positiva a partir de unos fragmentos de maxilar o mandíbula o incluso ante el hallazgo de piezas dentarias avulsionadas aisladas. En las Figuras 3 y 4 se establecen la diversidad de los hallazgos y la probabilidad de aparición de los mismos en cada pieza dentaria.
En el estudio de la codificación genérica, al ser ésta muy resumida (código sin restaurar, obturación, ausencia o corona), se tiende a rectificar muchos errores comunes intrínsecos al propio observador como por ejemplo la delimitación incorrecta de las superficies obturadas, el tipo de material empleado, la ausencia por extracción o por erupción de cordales, etc.
Analizando el código de pieza sin restaurar, las piezas dentarias que lo presentan con mayor frecuencia son los dientes anteroinferiores, seguidos de caninos superiores. Estas piezas al no poseer superficie oclusal son menos propensas a presentar procesos de caries susceptibles de obturaciones o, sufrir traumatismos directos al estar protegidos por la arcada superior. Por el contrario, los dientes con porcentajes más bajos son los primeros molares, cordales y segundos molares, más proclives a padecer patologías susceptibles de tratamiento por el odontoestomatólogo. El código de obturación es más frecuente en primeros, segundos molares, y en premolares, por la presencia anatómica de la superficie oclusal, unida a la gran participación de estos dientes durante el proceso de masticación. Opuestamente, las piezas con menores índices de obturaciones son las piezas anteroinferiores por los motivos expuestos anteriormente en el código de pieza sin restaurar. El código de ausencia presenta los índices más altos en el caso de los cordales y primeros molares. Con respecto a los cordales se resumen en el mismo código genérico las dos condiciones clínicas que más les afectan, que son la no erupción por condicionantes anatómicos y su tardía erupción, así como el consecuente tratamiento por extracción. En cuanto a los primeros molares, presentan unas frecuencias tan altas de ausencia por extracción, ya que al ser las primeras piezas en erupcionar son mas susceptibles a innumerables retratamientos que derivan en la perdida final del diente. Por el contrario, las piezas con menores índices de ausencias son nuevamente los incisivos y caninos inferiores, por la escasa afectación de procesos patológicos que sean motivo de extracción. Por último, el estudio del código de corona, se caracteriza por los bajos índices que presentan todas ellas. Cabe destacar los incisivos centrales como los de mayor frecuencia, debido a la importancia en la rehabilitación estética exigida por los propios pacientes. Por el contrario, las piezas con menor frecuencia de presentación de coronas son los cordales inferiores seguidos de los dientes anteroinferiores. En el caso de los cordales, es infrecuente la prescripción de una corona en piezas tan posteriores o malposicionadas optando tanto el paciente como el profesional por realizar la extracción antes que una posible rehabilitación. En los incisivos y caninos inferiores, las causas de frecuencias tan bajas son las mismas expuestas con anterioridad para los demás códigos estudiados.
En cuanto a la clasificación de las condiciones clínicas según su frecuencia, cualquier hallazgo genérico (obturación, ausencia o corona) encontrado en incisivos, caninos, o en los premolares inferiores tendría la consideración de «extraordinario», y teóricamente con 6 de ellos podríamos establecer una identificación positiva. El hallazgo de corona se considerara «extraordinario» estando presente en cualquiera de las 32 piezas dentarias. Por el contrario, los hallazgos con frecuencias mayores del 10%, considerados «ordinarios» son: obturación en los premolares superiores, y en todos los primeros y segundos molares, y ausencia en todos los primeros y los terceros molares (Tabla 4).
En el estudio de contralaterales, al analizar la codificación detallada, observamos como la probabilidad de presencia de hallazgos es idéntica en todas las parejas de contralaterales (Fig. 4). En cuanto a la diversidad de los códigos, las parejas también se comportan de forma idéntica, exceptuando la pareja 35-45 que presentan 24 y 30 códigos respectivamente (Fig. 3).
En la codificación genérica, en el estudio de contralaterales, si comparamos los códigos según sus frecuencias de presentación, comprobamos que hay similitudes entre si en las 16 parejas de contralaterales (Tabla 3), comportándose además de forma idéntica en la clasificación de sus hallazgos (Tabla 4). Los contralaterales que presentan mas similitudes entre si son los dientes anteroinferiores e incisivos laterales superiores; por el contrario los contralaterales con comportamientos más dispares son los molares inferiores y el primer molar superior (Fig. 5).
Conclusiones
Primera: En la población militar estudiada se ha encontrado que los molares superiores e inferiores y los premolares superiores son las piezas dentarias que presentan el mayor número de condiciones clínicas y la mayor diversidad de hallazgos. Por el contrario, los incisivos y caninos superiores e inferiores, así como los premolares inferiores, son las piezas con menor número y diversidad de hallazgos.
Segunda: Se han encontrado frecuencias de obturaciones superiores al 10% en los primeros y segundos molares superiores e inferiores y en los premolares superiores. También se han hallado frecuencias de ausencias dentarias superiores al 10% en los primeros y terceros molares superiores e inferiores.
Tercera: De un primer análisis de los resultados obtenidos en cuanto a la valoración de las codificaciones empleadas en este estudio (genérica versus detallada) se puede concluir que ambas codificaciones alcanzan un nivel similar de clasificación del hallazgo como ordinario o extraordinario.
Cuarta: Todas las piezas dentarias contralaterales poseen una tendencia a presentar el mismo comportamiento clínico, siendo casi idéntico (con diferencias de frecuencias inferiores al 1%), en incisivos y caninos inferiores, incisivos laterales superiores y cordales superiores.
Quinta: El establecimiento de la diversidad de condiciones clínicas que presentan las piezas dentarias en una determinada población resulta de inestimable valor para el establecimiento científico de la individualidad dental y, en consecuencia, se deduce el interés forense del estudio presentado y la necesidad de su continuidad.
Bibliografía
- Keiser-Nielsen S: Person identification by means of the teeth: a practical guide. 1ª ed. Editorial John Wright and Sons Ltd, Bristol, 1980.
- Luntz LL, Luntz P: Handbook for dental identification. 1ª ed. Editorial J.B. Lippincott Company, Philadelphia, 1973.
- Valenzuela Garach A, Martín de las Heras S: Odontología Forense. En: Gisbert Calabuig JA. Medicina Legal y Toxicología. 6ª ed. Editado por Villanueva Cañadas E., Masson, Barcelona, 2004. pp. 1310-1324.
- Keiser-Nielsen S: Dental identification: certainty v probability. Forensic Sci.1977; 9(2): 87–97.
- Valenzuela A, Martin de las Heras S, Marques T, Expósito N, Bohoyo JM: The application of dental methods of identification to human burn victims in a mass disaster. Int J Legal Med. 2000; 113(4): 236 239.
- Keiser-Nielsen S: Dental investigation in mass disasters. J Dent Res. 1963; 42: 303–11.
- Stewart TD: New developments in evaluating evidence from the skeleton. J Dent Res. 1963; 42: 264–73.
- Bandelt H-J, Quintana-Murci L, Salas A, Macaulay V: The fingerprint of phantom mutations in mitochondrial DNA data. Am J Hum Genet. 2002; 71: 1150-60.
- Bandelt H-J, Salas A, Bravi CM: Problems in FBI mtDNA database. Science. 2004; 305: 1402-4.
- Phillips C et al., Inferring ancestral origin using a single multiplex assay of ancestry-informative marker SNPs. Forensic Sci Int Genetics. 2007, 1:273-80.
- Adams BJ: Establishing personal identification based on specific patterns of missing, filled, and unrestored teeth. J Forensic Sci. 2003; 48(3): 487-496.
- Adams BJ: The diversity of adult dental patterns in the United States and the implications for personal identification. J Forensic Sci. 2003; 48(3): 497-503.
- Friedman RB, Cornwell KA, Lorton L: Dental characteristics of a large military population useful for identification. J Forensic Sci. 1989; 34(6): 1357–1364.
- Lee SS, Choi JH, Yoon CL, Kim CY, Shin KJ: The diversity of dental patterns in the orthopantomography and its significance in Human identification. J Forensic Sci. 2004; 49 (4): 784 786.
- Martín de las Heras S, Valenzuela A, Luna JdeD, Bravo M: Dental patterns in forensic dentistry. Are they useful for identification? Int J. Leg Med. 2009. En prensa.
- Taroni F, Mangin P, Perrior M: Identification concept and the use of probabilities in forensic odontology: An approach by philosophical discussion. J Forensic Odontostomatol. 2000; 18(1):15-18.
- Lorton L, Langley WH: Decision-making concepts in postmortem identification. J Forensic Sci.1986; 31 (1):190–6.
- Martín de las Heras S, Valenzuela A, Villanueva E, Marques T, Expósito N, Bohoyo JM: Methods for identification of 28 burn victims following a 1996 bus accident in Spain. J Forensic Sci. 1999; 44(2): 428-431.
- Bell GL: Dentistry’s role in the resolution of missing and unidentified persons cases. Dent Clin North Am. 2001; 45(2): 293–308.
- Sognnaes RD: Forensic stomatology (third of three parts). N Engl J Med. 1977; 296(4):197–203.
- Andersen L, Juhl M, Solheim T, Borrman H: Odontological identification of fire victims-potentialities and limitations.Int J Legal Med.1995; 107(5): 229-34.
- Martín A, Luna JdeD: Bioestadística para las ciencias de la salud. Ediciones Noma, S.A., Madrid, 1989.
Dirección para correspondencia:
Dra. Aurora Valenzuela Garach,
Departamento de Medicina Legal y Forense, Universidad de Granada,
Avenida de Madrid 11, 18012 Granada.
E-mail: agarach@ugr.es.